
Machine Learning is defined as the study of computer algorithms that automatically improve by using the data available as well as learning from its past experiences. Simply put, it is a process which enables the machines to learn automatically without actually being programmed to. While programs have a definite code that it will follow while executing, machine learning learns, identifies and analyses the data that has been input and takes decision based on the patterns of the dataset.
Machine Learning is a branch of Artificial Intelligence. It is based on the simple idea that any machine can identify patterns, learn and make decisions to execute commands with little human interference. While Artificial Intelligence allows a machine to simulate near human-like behaviour in real-time, Machine Learning is limited to just analysing patterns and takes decisions based on that.
The term ‘Machine Learning’ was coined in the year 1959 by an American IBM employee Arthur Samuel. Over the next two decades, the interest in machine learning, particularly in pattern recognition continued to rise, and in 1981, teaching strategies were developed such that the any neural network can learn to recognise up to 40 characters, which included the 26 alphabets, the 10 numbers and 4 special symbols. Modern-day machine learning has two main objectives – to classify the given data based on models that have already been developed, and to make predictions for future outcomes based on the said models.
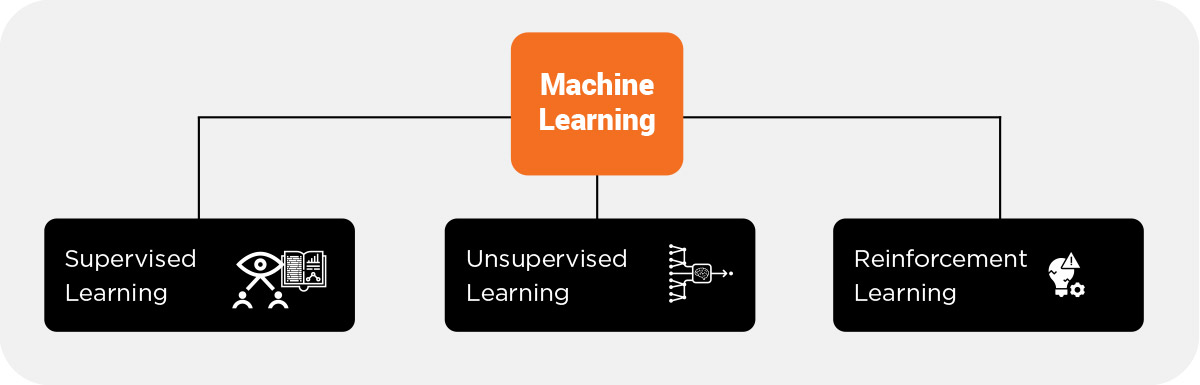
The Machine Learning traditionally has three methods:
1. Supervised Learning – This method uses algorithms which are trained using labelled data points. Here, the algorithm receives a set of input, called learning inputs, as well as its corresponding correct outputs. The algorithm then follows it up by comparing the correct outputs with the actual outputs that it generated. Methods such as prediction, classification, regression and gradient boosting use the patterns predict the values of any label in an unla-belled data. It is commonly used in areas where the previous data is used to predict the future events.
Note: If a part of the data that is used for training is unlabelled, then in place of Supervised Learning, Semi-supervised Learning is adopted. It is generally used when the cost of labelling the data proves to be costly, and thus only a small portion is labelled.
2. Unsupervised Learning – In this method, the data has no history of being labelled. Unlike in supervised learning, the machine is not provided with correct output to compare with. The aim of this mode of learning is to allow the machine to explore the data set and learn by itself. Techniques such as nearest-neighbour mapping, single value decomposition, k-means clustering and self-organising maps are used. This method is usually used in recommen-dation programs and to identify data outliers.
3. Reinforcement Learning – This method does not involve any explicit inputs or outputs. Rather, it relies on the machine’s interaction with its dynam-ic environment and conducts trial and error runs to determine the run which yields greatest reward. This mode of learning has three primary components:
a. The agent – responsible for learning and making decisions.
b. The environment – anything that the agent interacts with.
c. The action – the resultant reactions that the agent does.The main aim of this mode is to allow the machine to choose the actions that will yield the maximum results in a given time period.
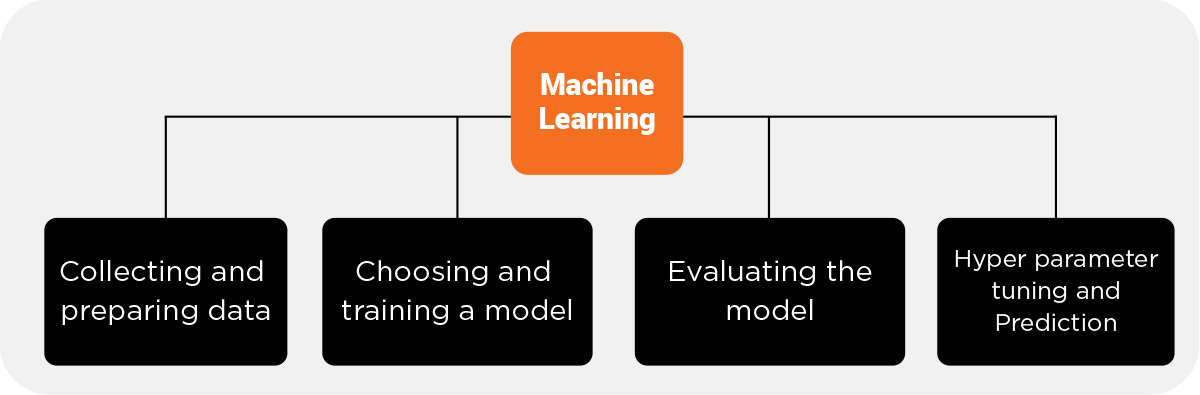
All the Machine Learning algorithms follow a simple four step procedure:
1. Collecting and preparing data – The first step for any ML algorithm involves feeding data (or the knowledge) into the machine, which is divided into two parts – training and testing data. The division of data is usually in the 80/20 or 70/30 ration to ensure proper testing once the model is built.
2. Choosing and training a model – The scientists of Machine Learning have already created different models for machines to solve various different problems. Therefore, it is imperative to choose the correct model in order to solve the problem.
3. Evaluating the model – Here, the machine learns from the training data set and trains itself to take decisions such as classifying or predicting data. In order to check its accuracy, the predictions are tested against the testing data.
4. Hyper parameter tuning and Prediction – These are the parameters which cannot be estimated by the model, but are still relevant and therefore need to be considered. These parameters are specified by the user.
These steps, when successfully executed, create a machine learning algorithm. The foundations of the code for Machine Learning are built from Python. Libraries such as Scikit-learn, TensorFlow and Keras are commonly used to code.
Machine Learning has been integrated into various fields over the past years. Online shopping websites such as Amazon and Flipkart use ML to recommend items based on previous purchases as well as browsing history. The Healthcare system utilises ML of smart wearable devices to monitor health of patients in real-time. It also aids in analysing data to predict any life-threatening disease at an early stage. The financial sector relies on ML for two main reasons: identifying important insights which can help investors, and prevent fraud by mining data.
With the rise in adoption of AI across various domains, machine learning has now become a staple subject to be dealt with. As such, professionals have started to recognise the importance of this field, since Machine Learning is an important part of Artificial Intelligence. It won’t be long before Machine Learning becomes a core subject that will be required in every field, irrespective of domain it is being applied in.



